Tutorial, Step 3: Create Expectations
 |  |  | |  | |  |
- Completed Step 2: Connect to Data of this tutorial.
The CLICommand Line Interface will help you create your first Expectation SuiteA collection of verifiable assertions about data.. Suites are simply collections of Expectations. In order to create a new suite, we will use the built-in ProfilerGenerates Metrics and candidate Expectations from data. to automatically create an Expectation Suite called getting_started_expectation_suite_taxi.demo.
Create an Expectation Suite using the CLI
Since we are using the CLI, you will want to return to your console and the ge_tutorials folder. Remember: This is where we initialized our Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components., and the Data Context is our access point to everything else in Great Expectations!
From the ge_tutorials folder, type the following into your terminal:
great_expectations suite new
This will bring up the following prompt:
How would you like to create your Expectation Suite?
1. Manually, without interacting with a sample batch of data (default)
2. Interactively, with a sample batch of data
3. Automatically, using a profiler
: 3
In this tutorial we will be using a Profiler to populate the Expectation Suite, so go ahead and enter 3 and hit enter to continue to the next prompt.
A batch of data is required to edit the suite - let's help you to specify it.
Which data asset (accessible by data connector "default_inferred_data_connector_name") would you like to use?
1. yellow_tripdata_sample_2019-01.csv
2. yellow_tripdata_sample_2019-02.csv
: 1
The Profiler will require a BatchA selection of records from a Data Asset. to analyze. This prompt is asking us which data to use for that. As you can see, the prompt it is giving corresponds to the .CSV files in our data folder. These are the very same ones we configured our DatasourceProvides a standard API for accessing and interacting with data from a wide variety of source systems. to connect to back in Step 2: Connect to Data.
We're going to choose the first file. If you're wondering why, here's an explanation: Recall that our data directory contains two CSV files: yellow_tripdata_sample_2019-01 and yellow_tripdata_sample_2019-02.
yellow_tripdata_sample_2019-01contains the January 2019 taxi data. Since we want to build an Expectation Suite based on what we know about our taxi data from the January 2019 data set, we want to use it for profiling.yellow_tripdata_sample_2019-02contains the February 2019 data, which we consider the “new” data set that we want to validate before using in production. We’ll use it later when showing you how to validate data.
Makes sense, right?
Go ahead and answer 1 and hit enter now. That will bring up the next prompt.
Name the new Expectation Suite [yellow_tripdata_sample_2019-01.csv.warning]: getting_started_expectation_suite_taxi.demo
This prompt is asking for a name for our new Expectation Suite. You can name it whatever you would like, but since this is the Getting Started Tutorial, we're demonstrating how to create an expectation suite, and we're using NYC taxi data we've used getting_started_expectation_suite_taxi.demo as the provided name.
Once you've provided a name for your Expectation Suite and hit enter, you will receive one more prompt. This one will ask if you want to proceed with creating the Expectation Suite as you've specified so far:
Great Expectations will create a notebook, containing code cells that select from available columns in your dataset and
generate expectations about them to demonstrate some examples of assertions you can make about your data.
When you run this notebook, Great Expectations will store these expectations in a new Expectation Suite "Name the new Expectation Suite [yellow_tripdata_sample_2019-01.csv.warning]: getting_started_expectation_suite_taxi.demo" here:
<Path of your project folder>/ge_tutorials/great_expectations/expectations/Name the new Expectation Suite [yellow_tripdata_sample_2019-01/csv/warning]: getting_started_expectation_suite_taxi/demo.json
Would you like to proceed? [Y/n]: Y
When you answer with Y (or just press enter) Great Expectations will open a Jupyter Notebook that helps you populate the new suite.
Creating Expectations in Jupyter Notebooks
Notebooks are a simple way of interacting with the Great Expectations Python API. You could also just write all this in plain Python code, but for convenience, Great Expectations provides you some boilerplate code in notebooks.
Since notebooks are often less permanent, creating Expectations in a notebook also helps reinforce that the source of truth about Expectations is the Expectation Suite, not the code that generates the Expectations.
Let’s take a look through the notebook and see what’s happening in each cell
Cell 1
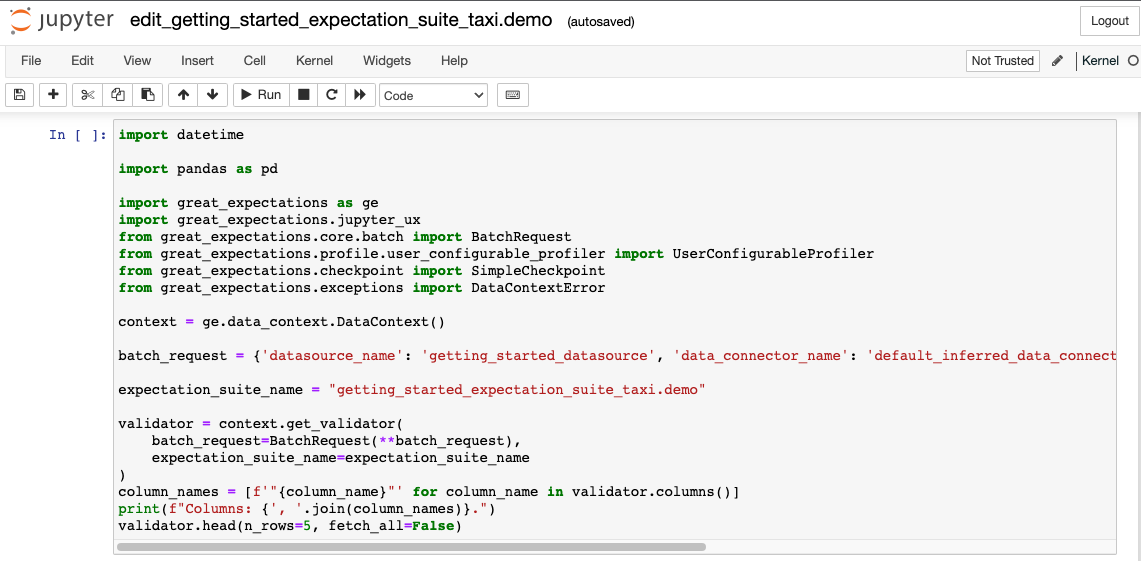
- The first cell does several things: It imports all the relevant libraries, loads a Data Context, and creates a
Validator, which combines a Batch RequestProvided to a Datasource in order to create a Batch. to define your batch of data, and an Expectation Suite.
Cell 2
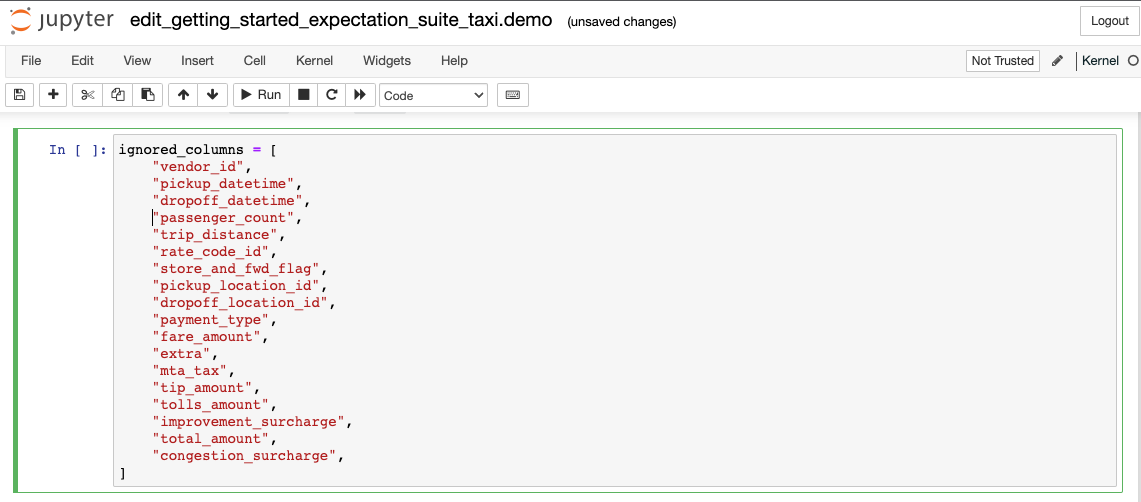
- The second cell allows you to specify which columns you want to ignore when creating Expectations. For our tutorial, we're going to ensure that the number of passengers recorded in our data is reasonable. To do this, we'll want our Profiler to examine the
passenger_countcolumn and determine just what a reasonable range is based on our January data. Let’s comment just this one line to include it:
ignored_columns = [
"vendor_id",
"pickup_datetime",
"dropoff_datetime",
# "passenger_count",
Cell 3
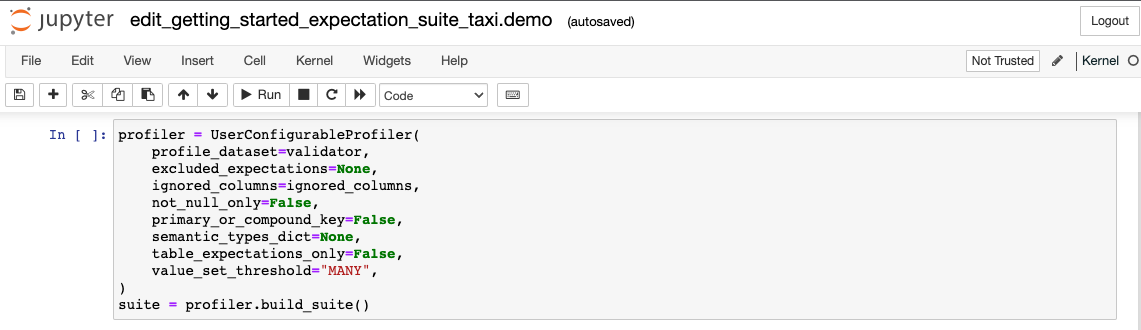
- The next cell is where you configure a
UserConfigurableProfilerand instantiate it, which will then profile the data and create the relevant Expectations to add to yourtaxi.demosuite.
Cell 4
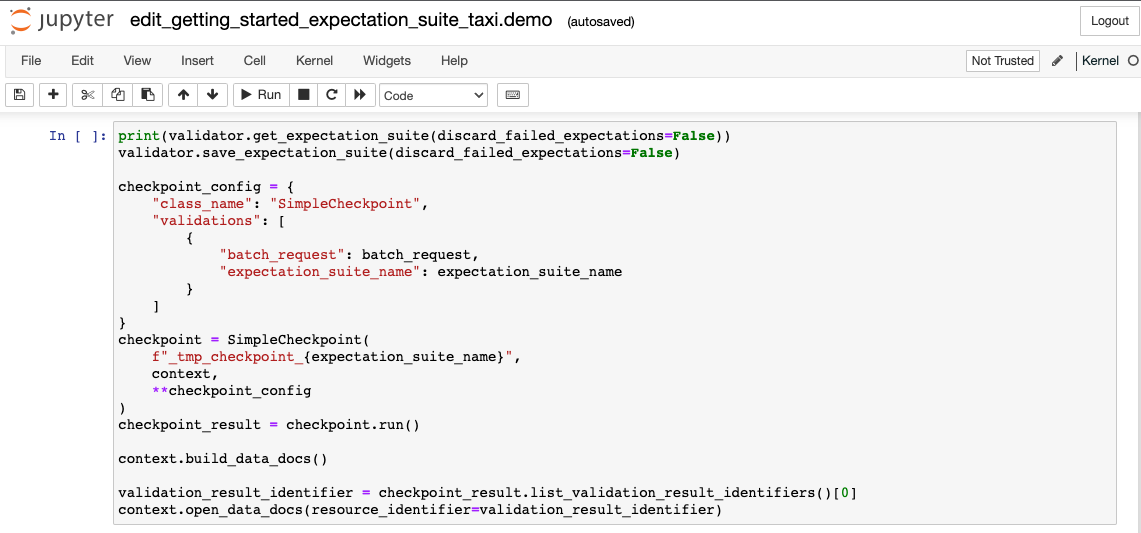
- The last cell does several things again: It saves the Expectation Suite to disk, runs the ValidationThe act of applying an Expectation Suite to a Batch. against the loaded data batch, and then builds and opens Data Docs, so you can look at the Validation Results. We will explain the validation step later in the next step, Step 4: Validate Data.
For purposes of this tutorial, the default values in all of these cells (except for the second one, which we changed to include the passenger_count field) provide the configurations and execute the steps that we need them to. So as long as you've made that one change, you're ready to continue.
Let’s execute all the cells and wait for Great Expectations to open a browser window with Data Docs, which will then let us see and edit the Expectations that were composed for us by the Profiler.
Viewing your Expectations in Data Docs
Once the Profiler is done executing it will open up Data DocsHuman readable documentation generated from Great Expectations metadata detailing Expectations, Validation Results, etc. in your browser automatically.
Data Docs translate Expectations, Validation ResultsGenerated when data is Validated against an Expectation or Expectation Suite., and other metadata into clean, human-readable documentation. Automatically compiling your data documentation from your data tests in the form of Data Docs guarantees that your documentation will never go stale. Feel free to take a moment to browse through the Expectations that the Profiler put together from the data that we provided it.
In particular, take a look at the Expectations that were created for the passenger_count field. These are the rules that we will be comparing the February data against when we validate it in step four of this tutorial.
How did we get those Expectations?
You can create and edit Expectations using several different workflows. Using an automated Profiler as we just did is one of the quickest options to get started with an Expectation Suite.
This Profiler connected to your data (using the Datasource you configured in the previous step), took a quick look at the contents of the data, and produced an initial set of Expectations. The Profiler considers the following properties, amongst others:
the data type of the column
simple statistics like column min, max, mean
the number of times values occur
the number of
NULLvalues
These Expectations are not intended to be very smart. Instead, the goal is to quickly provide some good examples, so that you’re not starting from a blank slate.
Creating Custom Expectations
Later, you should also take a look at other workflows for creating Custom Expectations. Creating Custom Expectations is an active area of work in the Great Expectations community. Stay tuned for improvements over time.
For the purposes of this tutorial, the Expectations created by the Profiler are all we need. On to Step 4: Validate your data!